
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 게임개발
- 게임
- 온라인
- 동적 힙
- 스펙주도형개발
- 바이브코딩
- C언어
- js
- 클린 아키텍처
- Unity
- 게임제작
- 캐스팅연산자
- 게임은 문화
- 파일패킹
- 2D
- handtracking
- 메모리
- PointableCanvasModule
- VR플랫폼
- 캐시 메모리 사상
- TCP
- OculusInteractionSamplesRayCanvas
- PHOTON
- VR
- 유니티
- C++
- MacFilter
- DAIVerse
- linux
- 5G에그
- Today
- Total
kunyoungparkk
음악에 반응하는 GLSL 쉐이더 코드 생성 모델 제작기 본문
음악에 반응하는 GLSL 쉐이더 생성 모델을 제작하기위해,
AI 파인튜닝을 진행했던 과정을 정리해보고자 합니다.
아래와 같은 방법으로 파인튜닝한 모델을 바탕으로 서빙하여 서비스를 만들어봤지만,
결국은 서비스의 품질을 위해 상용 LLM API + 프롬프트 튜닝을 활용하는 방향으로 변경했습니다.
그러니 이건 어쨋거나 실패 과정이라고 볼 수 있을 것 같습니다.
추론 시 범용적인 입력이 필요한 도메인은, 파인튜닝을 통해 성능을 개선한다는 것이 매우 어려운 것 같습니다.
이미 훌륭하게 학습된 LLM 모델에, 애매한 양의 데이터로 파인튜닝을 시도하면,
도메인과 관련된 부분에 대해서 일부 성능 개선이 되지만,
본래 모델이 잘 갖고 있던 토큰들의 의미도 함께 왜곡되는 문제가 있었습니다.
(범용성에 걸맞는 수많은 데이터가 있지 않는 이상..)
아마 앞으로는 AI를 활용하더라도 모델 자체를 만들고 파인튜닝하기보다는,
최대한 모델을 잘 활용할 방법을 찾을 것 같습니다.
이번 글은 데이터 수집, 모델 선정, 파인튜닝, 강화학습, 양자화, 모델 서빙 순으로 작성했습니다.
데이터 수집 및 전처리
1. 수집
- vertexshaderart 사이트 크롤링 툴 제작 (바이브 코딩 활용)
- LLM(Claude3.7 sonnet, GPT5)을 이용한 데이터 수집
2. 전처리
1) 클렌징
- compile 실패, 렌더링 실패 걸러주는 툴 제작

- 수작업으로 살릴 수 있는 쉐이더들은 살림. (공통된 에러 원인 등)
2) 라벨링
- vertexshaderart 사이트 라벨링 툴 제작 (VisualSong 렌더러 기반 React 프로그램, 바이브코딩 활용)

모델 선정
llama, gemma, deepseek, Qwen 등 다양한 오픈소스 모델이 있었지만,
최근 reddit 등의 커뮤니티와 AI 코딩 벤치마크를 참고해본 결과,
qwen 2.5 coder 32b instruct 모델을 사용했습니다.
파인튜닝
QLoRA를 활용해 학습했습니다.
아래는 코랩 A100 VRAM 80GB 환경에서 6시간 30분 동안 학습하는 코드입니다.
# Quantization config 세팅 -> 모델이 사용하는 vram을 최소화하기
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
model_name = "Qwen/Qwen2.5-Coder-32B-Instruct"
# 모델과 토크나이저 불러오기
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto",
attn_implementation="flash_attention_2", #runpod: sdpa
dtype=torch.bfloat16,
quantization_config=bnb_config
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.padding_side = 'right'
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
model.config.pad_token_id = tokenizer.pad_token_id
model.config.use_cache = False
torch.backends.cuda.matmul.allow_tf32 = True
torch.set_float32_matmul_precision("high")
peft_config = LoraConfig(
r=32,
lora_alpha=64,
lora_dropout=0.05,
bias="none",
target_modules=["q_proj", "o_proj",
"k_proj", "v_proj",
"up_proj", "down_proj",
"gate_proj"
],
task_type="CAUSAL_LM",
)
sft_args = SFTConfig(
output_dir="Qwen2.5-Coder-32B-Instruct-VS",
num_train_epochs=2,
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
gradient_checkpointing=True,
optim="adamw_torch_fused", #"paged_adamw_8bit",
logging_steps=10,
save_strategy="epoch",
learning_rate=1e-4,
bf16=True,
tf32=True,
max_grad_norm=0.3,
warmup_ratio=0.03,
lr_scheduler_type="cosine",
report_to="wandb",
max_length=3072,
packing=False,
dataset_text_field="text"
)
trainer = SFTTrainer(
model=model,
args=sft_args,
train_dataset=dataset,
peft_config=peft_config,
processing_class=tokenizer,
)
강화학습
이번에 크롤링해서 얻은 데이터를 제외하고는,
GPT5와 claude 3.7 sonnet을 이용해 데이터를 수집했습니다. (기존에 만들어놓은 프롬프트를 활용할 수 있었기 때문에)
그런데 한눈에 보기에도 GPT5의 결과가 대부분 더 좋았습니다.
학습한 데이터의 품질이 다 같지만은 않다는 사실을 모델에 알려줘야만 했습니다.
여러 방법이 있겠지만, 강화학습을 적용해보면 좋겠다 싶었습니다.
같은 프롬프트(primitive mode / 사용자 request) 정보에 대해, 두 모델 API를 통해 각각 데이터를 다르게 만들 수 있는 환경이었기 때문입니다.
물론 100% GPT5가 더 좋다고는 못하겠지만, 라벨링한 결과 3:1 정도로 대부분의 경우에 GPT5의 결과가 더 좋았습니다.
claude 3.7 sonnet 의 데이터가 더 좋았던 것은 대부분 GPT5가 제대로 만들지 못했던 경우였습니다.
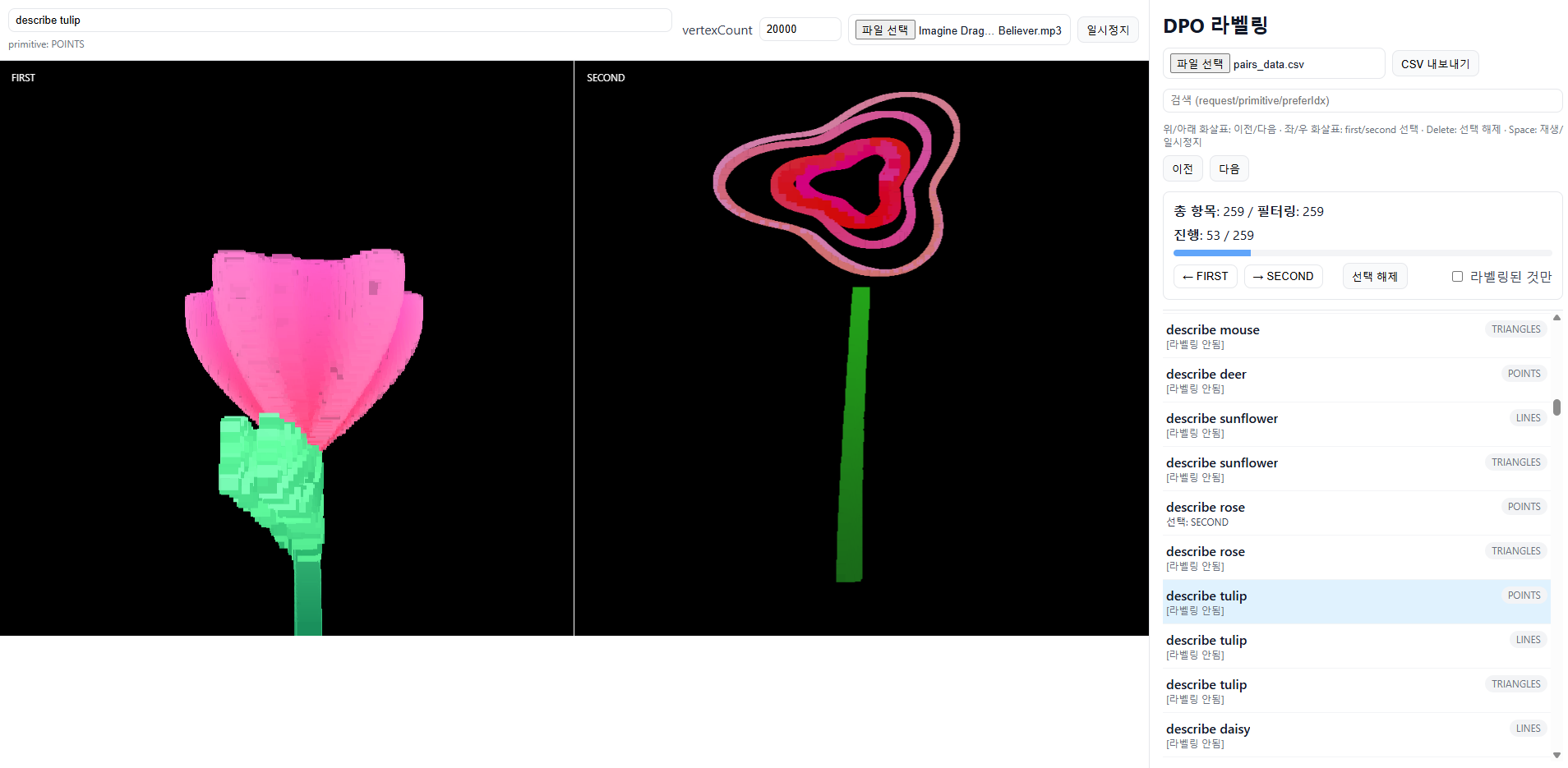
DPO 기반 데이터 수집 : 주로 같은 prompt로 claude / gpt5에 요청한 결과를 갖고 수집
1) 같은 request / primitiveMode를 갖는 데이터 쌍을 csv로 추출하는 툴 제작

2) 라벨링 툴 제작 : 동시에 VisualSong으로 같은 프롬프트로 생성된 다른 데이터 쌍을 보고, 이를 사용자가 라벨링하게끔 하는 툴.
import torch
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
from trl import DPOTrainer, DPOConfig
from peft import PeftModel, prepare_model_for_kbit_training
base_ckpt = "Qwen/Qwen2.5-Coder-32B-Instruct"
lora_adapter = "kunyoungparkk/Qwen2.5-Coder-32B-Instruct-VS-ver0.3-Only-LoRA"
tok = AutoTokenizer.from_pretrained(base_ckpt, trust_remote_code=True)
if tok.pad_token is None:
tok.pad_token = tok.eos_token
tok.padding_side = "right"
bnb_cfg = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=(torch.bfloat16 if torch.cuda.is_available() else torch.float16),
)
common_kwargs = dict(
quantization_config=bnb_cfg,
device_map="auto",
trust_remote_code=True,
attn_implementation="flash_attention_2",
)
policy_base = AutoModelForCausalLM.from_pretrained(base_ckpt, **common_kwargs)
policy_base.config.use_cache = False
policy_base = prepare_model_for_kbit_training(policy_base, use_gradient_checkpointing=True)
policy = PeftModel.from_pretrained(policy_base, lora_adapter, is_trainable=True)
# ref = AutoModelForCausalLM.from_pretrained(base_ckpt, **common_kwargs)
# for p in ref.parameters():
# p.requires_grad = False
# ref.eval()
args = DPOConfig(
output_dir="./dpo-out",
per_device_train_batch_size=1,
gradient_accumulation_steps=8,
learning_rate=1e-5,
num_train_epochs=1,
logging_steps=10,
bf16=True,
optim="paged_adamw_8bit", # "adamw_torch_fused"
max_length=6144, # (prompt + response) 총 길이
remove_unused_columns=False,
beta=0.2,
reference_free=True
)
trainer = DPOTrainer(
model=policy,
ref_model=None,
args=args,
train_dataset=ds_chat,
processing_class=tok,
)
trainer.train()
A100 VRAM 80GB에서 돌리는데도, 1에폭에 ref 모델 없이 겨우 돌렸다. (77GB 점유..)
위에서 제작한 라벨링 툴로 데이터를 제작했고,
강화학습 용 데이터 쌍은 500개 조금 넘는 정도로 크지 않았지만, 그래도 loss가 줄어드는 것을 볼 수 있었습니다.

TRIANGLES 모드의 매시 표현이나, 사운드텍스처의 자연스러운 흐름을 효과에 담아내는 것(여러 부분을 부드럽게 샘플링), 더 아름답게 효과를 만드는 것에 성공했지만, 음악에 제대로 반응하지 않게 됐습니다.
(이전 시간의 오디오에대해 생각하게 강화학습한 탓인듯.)
양자화
AWQ 양자화 방법을 활용했습니다.
- autoawq 라이브러리 사용
-> 주의: torch 버전을 2.6.0으로 낮춰야 함. (이후 버전 지원 x)
- calibration data 제작
calibration 과정은, "이 레이어는 어느 구간에서 값이 많이 나오니까, 이 구간을 잘 표현할 수 있게 4bit로 압축하자"를 정하는 과정. 그래서 실제 인풋의 배열을 넣어주면 됨. 다만 위에서 언급했듯이 calibration_samples의 크기에 따라 양자화 속도는 선형적으로 증가합니다. 현재 기준 256~512개 정도 입력 샘플 주면됐습니다.
모델 서빙
runpod vllm endpoint 옵션을 활용했습니다.
토크나이저도 레포에 포함 필요했고,
awq 양자화의 경우 bfloat vllm에서 지원하지 않아서, float16 옵션을 줘야했습니다.
• Trust Remote Code: True
• Download Directory: /runpod-volume/hf-cache
• Quantization: AWQ
• Max Model Length: 6144 (프롬프트+응답 합)
• Enable LoRA: True
• Max Num Seqs: 1 ~ 2
• Max Num Batched Tokens: 7000
(대략 3k×2 + 약간의 여유)
• Enable Prefix Caching: True
• Max LoRA Rank: 모델 lora rank 넣기 (16, 32 등)