
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 스펙주도형개발
- 메모리
- 클린 아키텍처
- js
- 파일패킹
- TCP
- 동적 힙
- 게임제작
- Unity
- 게임은 문화
- 5G에그
- 게임개발
- 유니티
- 온라인
- PHOTON
- DAIVerse
- VR플랫폼
- 게임
- 2D
- MacFilter
- C언어
- handtracking
- linux
- VR
- C++
- 캐스팅연산자
- OculusInteractionSamplesRayCanvas
- 바이브코딩
- 캐시 메모리 사상
- PointableCanvasModule
- Today
- Total
kunyoungparkk
프로세스, 스레드, 동기화 본문
프로세스
실행 중인 프로그램을 프로세스라고 한다.
메모리 관점에서의 프로세스: 코드-데이터-힙-스택 영역과 레지스터 상태.
프로세스 상태 변화
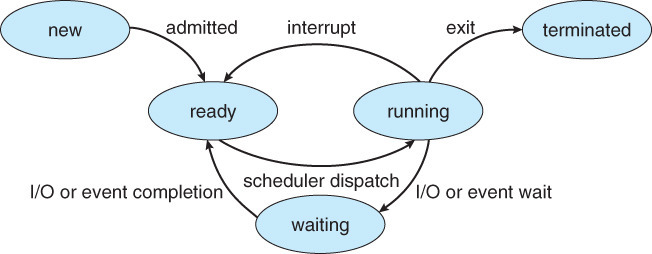
- new> ready: 프로세스 생성
- ready> running: 스케줄러가 해당 프로세스를 Run 시킴
- running > ready : 스케줄링 우선순위에서 밀렸거나 작업 완료
- run > waiting: 프로세스가 I/O 진행 등의 이유로 블락됨.
- waiting> ready : I/O 종료 등의 이유로 블락이 해제됨.
- waiting> terminated : 프로세스 종료
컨텍스트 스위칭
실행 중인 프로세스 변경 시, 작동하는 절차를 컨텍스트 스위칭이라고 한다. 구체적으로,
- 현재 프로세스의 context(register set 등)를 PCB에 저장
- 실행될 프로세스의 PCB에서 context를 복구
- 캐시와 TLB를 초기화
하는 과정을 거친다.
프로세스 스케줄링
멀티 프로세스를 동작시키기 위해서 스케줄러가 프로세스들의 상태를 변환시키는 과정이다.
CPU 이용율을 최대화하고(multiprogramming), 각 프로그램이 실행되는 동안 사용자가 상호작용을 할 수 있도록 하기 위해(time sharing) 필요하다.
Windows를 비롯한 대부분의 OS는 선점형(Preemptive) 스케줄링 알고리즘을 사용한다. (실행 중인 프로세스보다 우선순위가 높은 프로세스가 등장하면 즉시 조정).
비선점형(Non-Preemptive) 스케줄링 알고리즘은 우선순위가 높은 프로세스가 등장하더라도 실행 중인 프로세스가 CPU를 양보할 때까지 대기해야한다.
구체적으로 Windows OS는
1. 우선 순위가 동일한 프로세스들에 대해서는 라운드로빈 방식(타임슬라이스의 간격 동안 하나의 프로세스를 실행)으로 스케줄링 하고,
2. 우선순위가 다른 프로세스들에 대해서는 우선순위가 높은 것을 실행시킨다.
프로세스의 우선순위는 6계층으로 나뉘고, 우선순위 숫자가 높을 수록 우선순위가 높다.
SetClassPriority 함수로 프로세스 우선순위를 설정할 수 있다.
라운드로빈 방식으로 스케줄링하기 위해, 내부적으로 ready queue를 두어 ready 상태의 프로세스들을 관리한다.
이 ready queue는 논리 프로세서 당 존재한다. (논리 프로세서마다 각각 cpu역할을 하는 것이기 때문에 별도로 스케줄링되어야하므로 어찌보면 당연하다.)
스케줄러 동작 시점: 매 타임 슬라이스, 프로세스 생성 및 종료, 실행 중인 프로세스가 Block될 때
스케줄러 내부적인 작동 방법:
- 0번 타이머 인터럽트 발생 시 스케줄러 작동
- 현재 run 상태의 프로세스가 퀀텀 소비를 완료했는지 확인한다.
- 완료했다면, 디스패처 S/W 인터럽트를 발생시킨다.
- 디스패처는 ready queue의 높은 우선순위의 프로세스를 run 상태로 바꾸고, 기존 프로세스를 ready 혹은 waiting 상태로 변경한다. (컨텍스트 스위칭)
커널 오브젝트
리소스에 대한 중요한 정보를 담아둔 커널에서 관리하는 데이터 블록, 리소스의 수만큼 생성된다.
프로그래머는 커널 오브젝트의 핸들값(프로세스에 종속적)과, 시스템 함수로 커널 오브젝트에 간접 접근할 수 있다.
프로세스마다 프로세스가 접근할 수 있는 커널 오브젝트들의 핸들값과 실제 커널오브젝트를 이어주는 핸들 테이블이 존재한다.
Usage Count는 해당 리소스에 접근 가능한 핸들의 수. CloseHandle 함수로 핸들을 닫을 수 있으며(Usage Count 1 감소), Usage Count가 0이되면 해당 커널오브젝트를 OS가 소멸시킨다.
커널 오브젝트의 상태: Signaled, Non-Signaled의 두 가지 상태를 갖는다.
WaitForSingleObject 함수는 커널오브젝트가 Signaled 상태가 되면 반환한다. (Non-Signaled 상태일 때는 블락된다.)
ex) 프로세스(리소스의 일종)의 커널 오브젝트
프로세스 생성 시 Usage Count가 2가 된다. (부모와 자식 프로세스에)
프로세스 커널 오브젝트의 경우, 프로세스가 종료될 때 Signaled 상태가 된다.
GetCurrentProcess 함수의 경우에는 약속된 상수인 가짜 핸들값이 반환된다.
자식 프로세스에 핸들을 상속할 수 있으며, 리소스 생성 시에 해당 리소스의 핸들값을 자식 프로세스에 상속할지 결정할 수 있다. 이렇게 상속 설정된 핸들에 대해서만 상속된다. (당연하게도 상속 시에 상속 설정된 해당 리소스의 Usage Count가 증가한다.)
스레드
자신의 콜스택과 CPU 상태를 갖는, 수행의 단위이다.
위에서 프로세스 스케줄링에 대해 설명했지만, 실제 윈도우 OS의 스케줄링은 프로세스가 아니라 스레드 단위로 이루어진다.
- 동일 프로세스 내의 스레드들은 코드/데이터/힙 영역을 공유하기 때문에, 동일한 프로세스 내의 스레드들끼리 컨텍스트 스위칭 시 캐시를 비울 필요가 없다. 즉, 오버헤드를 줄인다.
- 스레드의 스택 사이즈는 기본 1MB이고, 이 이상으로 할당할 수도 있다.
- 한 프로세스에 여러 쓰레드가 존재하는 개념이고, 이 쓰레드들은 각각의 실행의 흐름으로서 스케줄링의 대상이 되며 위에서 언급한 프로세스 대신 스레드가 상태를 갖고 동작한다.
- 메인 스레드(main 함수 호출하는 스레드)가 종료될 때 프로세스가 종료된다.
- Windows OS에서는 커널 레벨 쓰레드를 지원하여, 쓰레드의 관리 주체는 커널이다.
- 커널 레벨 쓰레드이기 때문에, 쓰레드의 전환 시에 커널모드로 동작해야 하는데 이러한 모드 전환이 유저 레벨 쓰레드에 비해 시스템에 부담을 준다. 그러나 커널이 직접 쓰레드를 관리하기에 편리하고 안정적이다.
- 스레드의 Usage Count는 프로세스와 마찬가지로 생성 시에 2가 되고, 쓰레드 종료 시 하나가 감소하고, 쓰레드 핸들을 CloseHandle 시에 하나가 감소한다. 쓰레드 생성과 동시에 CloseHandle로 쓰레드 핸들을 닫는 것을 프로세스에서 쓰레드를 분리한다고 한다.
멀티 프로세스가 아닌 멀티 스레드를 이용하는 이유:
- 멀티 프로세스보다 적은 메모리 공간을 차지하고, context switching 오버헤드가 적다. (동일 프로세스 내의 스레드끼리 context switching을 진행할 경우 캐시와 TLB를 초기화하지 않아도 되기 때문이다.)
- 메모리를 공유하기 때문에 별도의 자원을 이용하지 않고도 스레드 간 통신이 가능하다.
스레드의 생성: CreateThread 함수를 통해 스레드를 생성한다.
스레드의 종료: return (가장 좋은 방법), ExitThread(쓰레드 내부에서 호출, 비추천), TerminateThread(쓰레드 외부에서, 절대 비추천)의 세 가지 방법 중 하나로 종료할 수 있다.
SuspendThread함수로 쓰레드를 Block시킬 수 있고, ResumeThread 함수로 Block된 쓰레드를 Ready 상태로 바꿀 수 있다. 이는 내부에서 suspend count를 각각 1씩 증/감하는 원리로 작동한다.
쓰레드의 우선순위: 쓰레드는 해당 쓰레드를 갖고있는 프로세스의 우선순위 + 쓰레드 각각의 상대적인 우선순위(-2~+2)를 합산해서 정해진다. 프로세스의 우선순위가 5 단위로 나누어져있기 때문에, 프로세스의 우선순위가 더 우선되고 그 후에 내부 쓰레드들의 우선순위로 우선순위가 결정되게 된다.
SetThreadPriority 함수로 쓰레드의 우선순위를 설정한다.
_beginthreadex, _endthreadex
C 라이브러리 함수 중 srand, strtok 함수의 경우 함수를 호출 시 어딘가에 값을 저장해놓는 방식임을 알 수 있다.
그러므로 같은 가상메모리를 가진 멀티스레드 환경에서, 위의 함수들을 그냥 사용하면 안전하지 않다.
그래서 등장한 것이 _beginthreadex, _endthreadex 함수이다.
위의 두 함수로 스레드를 생성 및 종료하여, 런타임 라이브러리를 thread-safe하게 사용할 수 있다.(추가로 VS 설정에서 멀티쓰레드 DLL 설정(쓰레드에 안전한 런타임 라이브러리 사용)을 하여 ANSI 함수를 안전하게 사용할 수 있다.)
물론 이 경우에도 _endthreadex보다 return으로 스레드를 종료하는 것이 좋다. _endthreadex로 스레드를 종료하면 스레드 함수 내부의 지역 객체들의 소멸자가 호출되지 않기 때문이다. return을 통해 종료하면 결국 _endthreadex를 내부적으로 호출되는 형태인데, 이는 밑의 작동원리에서 알아본다.
이 두 함수는 스레드 생성 시 독립적인 메모리 블록을 할당하고, 스레드 종료 시 이 공간을 해제하는 방식으로 구현된다.
좀 더 자세하게 알아보자.
_beginthreadex 작동 원리
- 스레드 함수 주소, 전달할 매개변수, 버퍼가 필요한 런타임 함수들의 버퍼 포인터 넣은 _tiddata 구조체를 만든다.
- CreateThread를 호출하고, CreateThread 내부에서 다시 _threadstartex 함수를 호출한다.
- _threadstartex 함수에서 TLS에 _tiddata를 저장한다. 이후 _callthreadstartex 함수를 호출하고 여기서 실제 스레드 함수를 호출한다.
- 스레드 함수가 종료된 후에(반환된 후에), _endthreadex를 호출한다. (return으로 스레드가 종료됐을 경우일 때를 가정한다. 만약 _endthreadex를 직접 호출했다면 이 절차대로 되지 않는다.)
- _endthreadex 함수 내부에서 _tiddata를 해제하고 ExitThread를 호출한다.
위의 절차를 통해 어떻게 return 시에 자동으로 스레드가 정리되는지도 알 수 있었다.
결국 CreateThread, ExitThread를 래핑하는 방식으로 구현됐으며, 실제 스레드 실행 시 스레드 함수 자체가 아닌, 스레드 함수를 래핑한 _callthreadex 함수를 호출했기 때문에, 스레드 함수가 return될 때 알아서 스레드가 정리될 수 있었다.
쓰레드 동기화
쓰레드의 동시 접근의 문제를 해결하기 위해 동기화를 한다.
쓰레드 동기화의 주체가 어디냐에 따라 크게 유저 모드 동기화와 커널 모드 동기화로 나뉜다.
유저 모드 동기화에는 인터락 함수를 이용한 스핀락, 크리티컬 섹션과 SRWLOCK의 세 가지 방법이 있고,
커널 모드 동기화에는 뮤텍스, 세마포어, 이름 있는 뮤텍스, 이벤트 기반, 타이머 기반 동기화가 있다.
역시나 유저 모드 동기화의 경우 속도가 빠르고(커널 모드 전환이 일어나지 않아서), 커널 모드 동기화의 경우 기능이 많다.
유저 모드 동기화에서 커널 모드 전환이 일어나지 않는다는 것은, 임계영역 진입 가능 여부를 확인할 때를 얘기하는 것이다. 진입 불가능할 때는 Block되기 때문에 커널 모드로 전환된다.
간단하게 증가 연산의 임계영역(1억번 반복), 두 쓰레드에 대해 동기화 속도 테스트를 해보니,
유저 모드 동기화와 커널 모드 동기화 간의 상당한 속도 차이가 발생했다.
스핀 락: 인터락 함수(InterlockedExchange)를 이용하여 공유되는 변수에 접근이 가능한지 loop를 돌면서 lock을 얻는 방식으로 구현한다. 이 방식의 장점이라면 lock을 얻을 수 있는 상황에서 즉시 lock을 획득할 수 있다는 점이다. 그러나 스레드가 퀀텀 내에 lock을 얻지 못하면 퀀텀동안 loop만 돌면서 소비해버리는 것이기 때문에, 퀀텀 안에 진입이 가능해지는 경우가 아니라면 성능에 좋지 않다. 추가로 특정 스레드를 우선시해야하는 상황에서 제한적으로 사용할 수 있다. (그럴 일은 거의 없다.)
인터락 함수: InterlockedIncrement 함수, InterlockedDecrement 함수 등 해당 연산의 원자적 접근을 보장한다. 크리티컬 섹션 함수 내부도 인터락 함수로 구현되어있다고 한다.
크리티컬 섹션: CRITICAL_SECTION 변수 선언 - InitializeCriticalSection 함수로 초기화 > EnterCriticalSection ~임계영역~ LeaveCriticalSection > DeleteCriticalSection 함수로 제거 순으로 작동한다.

실제 Critical Section 구조체 내부는 위 사진과 같다.
EnterCriticalSection 작동 방식
1) CriticalSection 구조체로부터 인터락으로 현재 다른 스레드가 임계영역을 점유하고 있는지 확인한다.
1-1) 점유하고 있지 않다면, 바로 return하여 현재 스레드가 바로 임계영역에 접근한다.
2) 이미 다른 스레드가 점유하고 있는 상황이라면 일정 횟수동안 스핀락 동작을 한다.
2-1) 스핀 락 동작 중에 lock을 획득하면 return하여 현재 스레드가 임계영역에 접근
3) 이벤트 커널 오브젝트를 이용하여 현재 스레드를 대기 상태로 만든다.
참고로 TryEnterCiriticalSection 함수를 이용하면, 위의 1번 동작을 하고나서 만약 다른 스레드가 점유중이더라도 바로 return 한다.
SRWLock: Slim Reader-Writer Lock의 방식으로, 크리티컬 섹션과 유사하지만 리소스의 값을 읽기만 하는 스레드(Reader)와 리소스의 값을 읽고 쓰는 스레드(Writer)가 완전히 구분되어 있는 경우에만 사용한다.
공유 리소스를 읽기만 하는 경우에는 리소스의 값을 변경하지 않기 때문에 동시에 수행되도 무방하기 때문에 크리티컬 섹션에 비해 성능이 좋다. (재귀적인 Lock이 불가능하고, TryEnter 함수가 없다는 단점이 있지만 크게 중요하지 않다.)
InitializeSRWLock 함수로 초기화를 진행하고,
AcquireSRWLockExclusive, ReleaseSRWLockExclusive 함수로 Writer 스레드의 임계영역을 감싼다.
AcquireSRWLockShared, ReleaseSRWLockShared 함수로 Reader 스레드의 임계영역을 감싼다.
SRWLock 오브젝트를 삭제하는 것은 시스템이 자동으로 수행해 준다.
std::Mutex가 이 SLWLock을 Wrapping 하여 구현됐다고 한다.
★CriticalSection, SRWLock 사용 시 팁
1) 원자적으로 관리되어야하는, 논리적으로 단일한 리소스는 모두 자신만의 하나의 락을 가져야한다.
2) 다수의 논리적 리소스들에 동시에 접근할 때, 각각의 락에 대한 접근 순서를 같게 해야한다. (데드락 방지)
3) 락을 너무 장시간 점유하지 말자.
뮤텍스: CreateMutex로 뮤텍스 생성하고 핸들을 얻어온다. > WaitForSingleObject ~ 임계영역 ~ ReleaseMutex > CloseHandle로 뮤텍스 제거.
뮤텍스를 반환하지 않고 쓰레드가 종료됐을 경우, OS 차원에서 해당 뮤텍스를 대신 반환해준다. 그 다음 접근하는 쓰레드가 뮤텍스를 획득할 때 WAIT_ABANDONED를 받는다.
세마포어: 뮤텍스와 유사하지만, 뮤텍스는 key가 1개인 반면 세마포어는 key가 여러개가 될 수 있어서, 임계영역에 접근하는 쓰레드 개수를 정할 수 있다. 따라서 뮤텍스는 세마포어의 일종이다.
이름있는 뮤텍스: 뮤텍스 생성 시 이름을 지정하고, 이 이름을 통해 타 프로세스와 해당 뮤텍스를 공유할 수 있다. OpenMutex 함수에 타 프로세스에 생성된 뮤텍스와 같은 이름을 인자로 넣으면 된다. 커널에서 뮤텍스 리소스를 관리하기 때문에 가능한 것.
이벤트 기반 동기화: 실행 순서를 동기화할 수 있다.
SetEvent 함수를 통해 NonSignaled 상태에서 Signaled 상태로 바꿀 수 있다.
그 다음 WaitForSingleObject 함수가 호출될 때, 이벤트의 상태가 자동으로 Non-Signaled 상태로 바뀌면 자동 리셋 모드이고, 자동으로 바뀌지는 않고 추가적으로 ResetEvent 함수 호출을 통해 Non-Signaled 상태로 바꾸는 구조가 수동 리셋 모드이다. CreateEvent 함수로 이벤트 객체 생성 시 인자로 수동리셋 or 자동리셋 모드를 설정한다.
수동 리셋 모드는 둘 이상의 쓰레드를 동시에 깨워서 실행해야 할 때 유용하다.
동시에 깨워서 예상과 결과가 다른 동기화 문제가 발생할 수 있다. 이때, 추가적으로 뮤텍스를 동시에 사용해서 동기화하여 이 문제를 해결할 수 있다.
타이머 기반 동기화: 정해진 시간이 지나면 자동으로 Signaled 상태가 되는 특성을 지니는 동기화 기법.
쓰레드의 실행시간 및 실행주기를 결정하려는 목적으로 사용한다. 수동 리셋 타이머와 주기적 타이머로 나뉜다.
CreateWaitableTimer로 타이머 생성(수동/자동 설정) > SetWaitableTimer 함수로 알람 시간(상대/절대 시간), 주기 시간(수동 리셋 타이머인 경우에는 0), 완료 루틴 설정 > CancelWaitableTimer로 타이머 중간에 해제 > CloseHandle
쓰레드 풀링: 쓰레드의 생성과 소멸에 생기는 시스템의 부담을 덜어 성능 향상의 목적으로 사용한다.
기본 원리는 쓰레드의 재활용으로, 할당된 일을 마친 쓰레드를 소멸시키지 않고, 쓰레드 풀에 저장해뒀다가 필요할 때 다시 꺼내서 일을 시키는 것이다.
[구현 예시] 생성된 쓰레드들은 event에 대해 WaitForSingleObject하고 있다가, 일이 등록될 때 event를 Signaled 상태로 바꾸고, 쓰레드들이 그 일을 하나씩 갖고가서 처리하게 한다. 그러다가 할 일이 없어지면 쓰레드들은 WaitForSingleObject에서 블락되게한다.
'Computer Science' 카테고리의 다른 글
| 캐시 메모리 (0) | 2021.11.08 |
|---|---|
| 메모리 (0) | 2021.11.08 |
| 어셈블리 관련 정리(x86) (0) | 2021.10.15 |


